The Moment That Started Everything
Open ChatGPT Type: “My name is Amit. I’m building a FastAPI backend with SQLite.”
Switch to Claude. Ask: “What stack am I using?”
Claude doesn’t know. Of course it doesn’t. You never told Claude. You told ChatGPT. Those are different products, different companies, different memory silos.
Your knowledge — your name, your project, your decisions, your preferences — is trapped inside whichever chat window you happened to use.
So you re-type it. Again. And again. Every model, every session, every tool.
This is the problem. Not a hypothetical one. Not a future concern. A daily, measurable, expensive friction that every AI power user experiences and most have simply learned to tolerate.
We decided to stop tolerating it.
The Scale of the Problem
Consider what happens across a typical week for someone who uses AI seriously:
- Monday: You explain your project architecture to ChatGPT while debugging.
- Tuesday: You switch to Claude for a code review — and re-explain the same
architecture. - Wednesday: You ask Gemini about deployment options — and re-explain again.
- Thursday: You open a new ChatGPT session (the old one is buried) — and
re-explain to the same model. - Friday: You’re in Cursor, using Copilot — and guess what? Re-explain.
Every re-explanation costs tokens. Every token costs money. Every repetition wastes time. And none of it compounds — your AI tools know less about you on Friday than a competent colleague would after one conversation.
This is memory fragmentation across LLM silos. It destroys continuity, inflates cost, and traps user knowledge inside proprietary platforms.
What If the Default Was Reversed?
Today’s AI chat works like this:
You ──► LLM ──► Response
(context re-sent every time)
You are the memory. The LLM is stateless. Every session starts from zero. The only thing that persists is whatever the platform decides to store — in a format you can’t export, with a model you can’t switch.
Now imagine the inverse:
You ──► Knowledge Layer ──► (optional) LLM ──► Response
│ │
│ └── only called when memory can't answer
└── retrieves from YOUR persistent knowledge base
The knowledge layer learns continuously from your conversations, your documents, your decisions. When you ask a question it already knows the answer to — from any previous session, with any model — it answers directly.
No LLM call. No tokens burned. No re-teaching.
The LLM becomes a cache miss. It’s called only when your personal knowledge base genuinely can’t answer.
This is the core idea behind PersonaGraph.

Three Paradigm Inversions
PersonaGraph isn’t a feature added to an existing LLM. It’s a fundamental rethinking of where intelligence and knowledge live in the AI stack. Three inversions define the architecture:
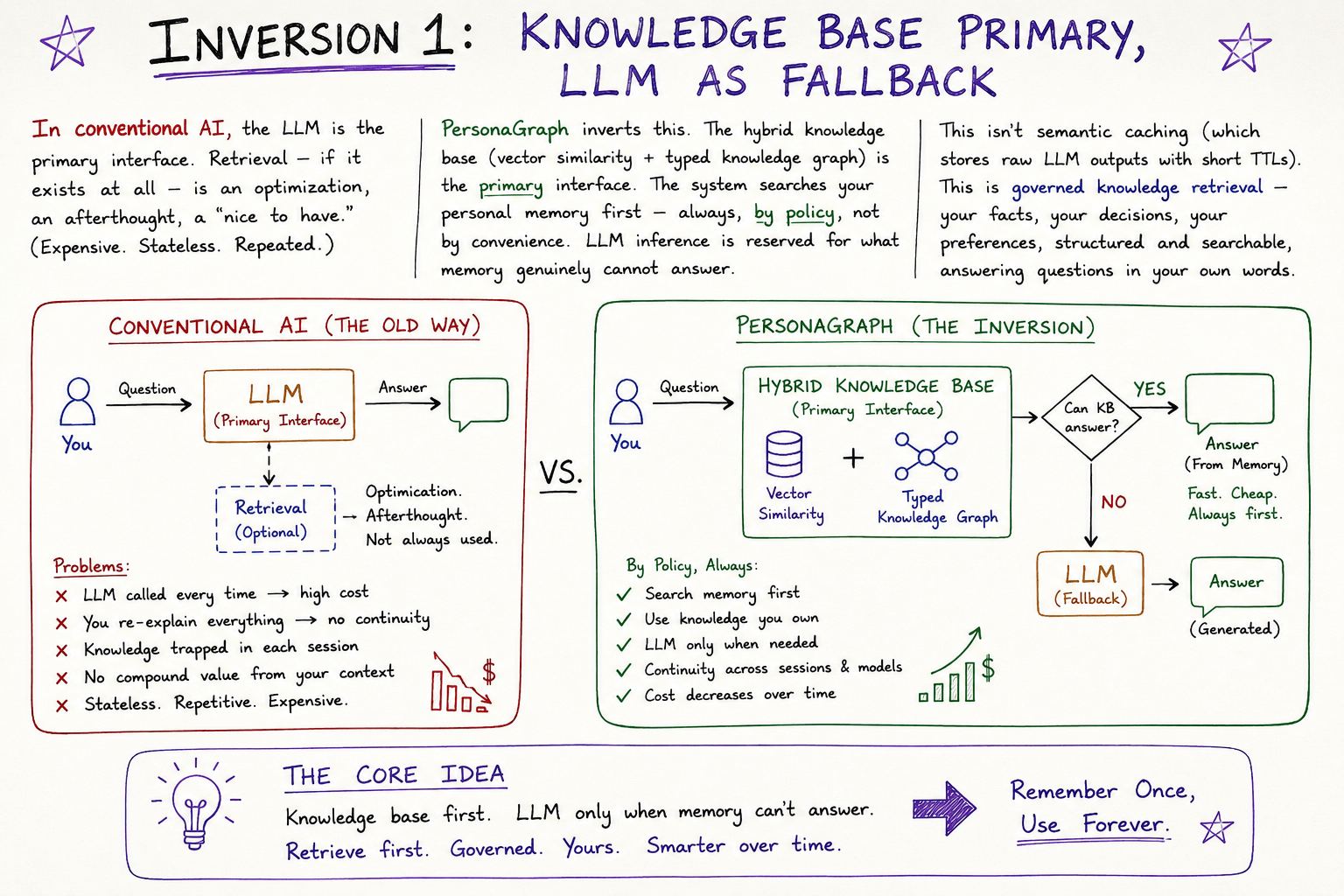
Inversion 1: Knowledge Base Primary, LLM as Fallback
In conventional AI, the LLM is the primary interface. Retrieval — if it exists at all — is an optimization, an afterthought, a “nice to have.”
PersonaGraph inverts this. The hybrid knowledge base (vector similarity + typed knowledge graph) is the primary interface. The system searches your personal memory first — always, by policy, not by convenience. LLM inference is reserved for what memory genuinely cannot answer.
This isn’t semantic caching (which stores raw LLM outputs with short TTLs). This is governed knowledge retrieval — your facts, your decisions, your preferences, structured and searchable, answering questions in your own words.
Inversion 2: User Owns Everything
Today, your AI memory is owned by the platform. ChatGPT’s memory? OpenAI’s servers, OpenAI’s format, OpenAI’s decision about what to remember and forget. Try exporting it. Try switching to Claude with your memory intact. Try running it offline.
PersonaGraph treats sovereignty as an architectural invariant, not a feature:
- Bring Your Own Keys (BYOK): Your API keys, encrypted, never stored in plaintext.
You’re the customer of each LLM provider — not us. - Local-first: The entire system runs on SQLite + local embeddings. Docker Compose
up, and it’s yours. No external services required. - Export your graph: Your knowledge is a structured asset you own — entities,
relations, memories with metadata. Not a proprietary blob.

Inversion 3: Cost Decreases Over Time
With conventional AI, cost scales linearly with usage. More questions = more tokens = more money. There is no compound return on your investment of context.
PersonaGraph inverts the cost curve. As your personal knowledge base matures:
- More queries hit L1–L3 (answered from memory, zero tokens)
- Cache hit rate rises
- Marginal cost per query falls
- Your AI gets cheaper and more knowledgeable over time
We call this compounding intelligence. The value of your knowledge base increases with use — honestly, after a cold-start period where you need to teach the system enough facts to be useful.

What PersonaGraph Is (and What It Isn’t)
Let’s be precise, because the AI memory space is crowded with overlapping claims.
PersonaGraph IS:
- A research architecture for persistent personal knowledge reuse across LLMs
- A retrieve-first system where your knowledge base is queried before any LLM
- A hybrid memory model combining vector search with a typed personal knowledge
graph - A measured contribution — we built it, benchmarked it, and published the gaps
honestly
PersonaGraph IS NOT:
- A new embedding model or graph database (we use existing components)
- A replacement for Mem0, LiteLLM, or any specific tool (different layer, different problem)
- A “GraphRAG for personal use” (GraphRAG solves document corpus QA — different problem entirely)
- A finished product with enterprise security (it’s a POC with honest architectural seams)
The novelty is in the synthesis: retrieve-first + typed hybrid personal memory + cross-LLM adapter sovereignty + consumer/self-host reference implementation + a benchmark that encodes reuse as a first-class metric.
Individual components exist. This combination — operationalized under Remember Once, Use Forever — does not.

The Two Names You’ll See in This Series
This project has two names, and they serve two purposes. Not a branding confusion — a deliberate
split:
| Name | What It Is | You’ll See It When |
|---|---|---|
| PersonaGraph | The research architecture — the what and why | Research posts, architecture diagrams, benchmarks, formal claims |
| Knowledge OS | The product / reference implementation — the how | Code, Docker, UI, demo, MCP server, “try it yourself” posts |
Think of it like MapReduce (the contribution) and Hadoop (the thing you run). PersonaGraph defines the architecture. Knowledge OS implements it.
The tagline — Remember Once. Use Forever. — belongs to Knowledge OS. PersonaGraph implements the principle.
Why We’re Publishing This as a Series
We could have dropped a single blog post with a GitHub link and called it a day. Instead, we’re
publishing this as an 8-part series, one post at a time, because:
- The research was hard, and we want to show the work. Nine phases of research
— landscape analysis, literature review, novelty classification, gap analysis, algorithm design, formal
mathematics. We’re not going to compress that into a tweet thread. - Honest claims require honest context. Our token savings are measured on some
benchmarks and simulated on others. Our security is POC-tier, not enterprise. Our extractors are rule-based
with an LLM-optional path. A single post would either overclaim or under-explain. A series lets us be
precise. - The problem deserves serious treatment. Memory fragmentation across LLM
silos isn’t a minor inconvenience — it’s a structural failure in how personal AI works today. That argument
needs space to develop.
What’s Coming Next
Over the next seven posts, we’ll walk through:
- Post #2: Why every LLM forgets you — and why that’s by design (the economics and incentives behind platform memory lock-in)
- Post #3: The L1–L4 retrieve-first engine — how “LLM as cache miss” actually works, with measured results
- Post #4: Five types of memory your AI should have — the typed ontology that makes retrieval precise
- Post #5: An honest comparison with Mem0, ChatGPT Memory, and the rest of the landscape
- Post #6: How we validated PersonaGraph — PKRB, the benchmark we built to measure Remember Once
- Post #7: Run it yourself — Knowledge OS in Docker, in 3 minutes, with zero API keys
- Post #8: What’s next — the roadmap, the open questions, and how to contribute
The One-Sentence Version
We introduce PersonaGraph, an architecture for persistent personal knowledge
reuse across LLMs, and Knowledge OS, its open self-hosted reference implementation — guided by Remember Once. Use Forever.
If that sentence resonates with a problem you have — you’re the audience. Stay for the series.
Happy Learning!!
Leave a Reply